源码将于论文发表后开源。
项目背景
深圳某港口的实际需求,港区的无人车需要根据车流情况提前规划路线,但同时港内又有很多外部车辆没办法统一通过GPS来管理,为了给无人车调度系统和管理人员提供决策支持,就有了全局平面追踪这样的需求。
先前已经由其他团队做了一版,用到了摄像头+激光雷达,但效果不太理想,才找到我们实验室。
整体架构
整个后端拆成了四个模块,通过 Kafka 和 ZeroMQ 串联:
前端 Dashboard / 无人车调度系统
▲ │
REST/WS │ │ 配置下发
│ ▼
┌──────────────────────────┐
│ HTTP Server (Go/Gin) │
└──┬───────────────┬───────┘
│ │
Kafka(识别结果) │ │ Kafka(控制指令)
│ ┌────┤
▼ ▼ │
┌──────────────┐ │
│ Vision │ │
│ (Python) │ │
└──────────────┘ │
▲ │
ZeroMQ(同步帧) │ │
│ │
┌──────────────┐ │
│Source Manager│◄──┘
│ (Go) │
└──────┬───────┘
│
多路 RTSP 视频流Source Manager——视频源统一管理
用 Go 写的视频源调度器。支持动态增删 RTSP 视频源,统一做帧同步和时间戳对齐,然后通过 ZeroMQ 把同步后的帧批量推给 Vision 模块。配置变更由 HTTP Server 通过 Kafka 的 control topic 下发,不用重启服务——前端改一下配置,几秒内生效。
Vision——多摄头智能识别
整个系统的算法核心,Python 实现,分三大块:
目标检测:基于 YOLO,支持车辆(区分型号、挂车状态)、移动机械(港区内部设备号)和人员检测。附带预标注工具和 CVAT → YOLO 训练流水线,Ray Tune 自动搜超参。
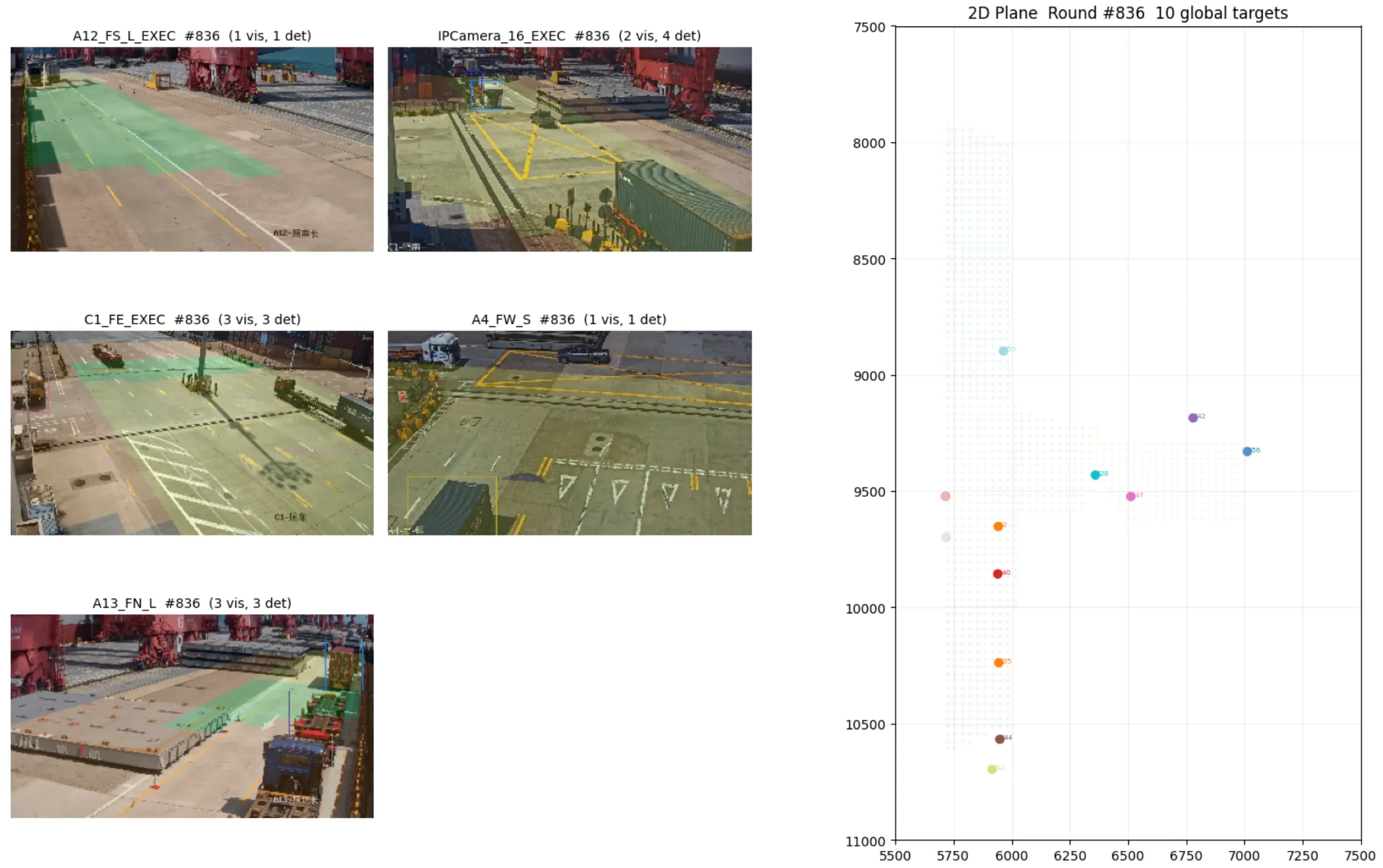
MCMVT 多摄头追踪:这套是花时间最多的部分。核心思路是「自治区 + 领地管理」
- 地理位置相邻的摄像头划成一个自治区,各自独立运行追踪器,天然适合分布式
- 世界坐标网格化,每个格点指定一个领主摄像头——谁的视角看这个位置最清楚,谁说了算
- 三级优先级掩码(CORE / BUFFER / BOUNDARY)控制轨迹的生命周期和跨摄头交接
- 四阶段匹配策略 + 世界坐标系 Kalman 滤波,轨迹平滑不掉
坐标映射:单应性矩阵反算,四个标定点 → 像素坐标到世界坐标的实时转换,配合出入口区域的事件触发。
HTTP Server——交互中枢
Go + Gin 写的 REST API 服务,是整个平台和外界交互的唯一入口。前端 Dashboard 和无人车调度系统都通过它来获取数据、下发指令。
- 视频源配置管理:前端增删改 RTSP 源、调整摄像头参数,API 校验后通过 Kafka 下发给 Source Manager,实时生效
- 实时目标查询:当前场内所有车辆/设备/人员的最新位置和状态(类型、车牌号、设备号、安全帽佩戴等)
- 历史轨迹回放:按时间范围和关键字(车牌号 / 设备号)检索目标的完整运动轨迹
- WebSocket 推送:识别结果实时推前端,比轮询有效率得多
- 统计面板:场内各类目标总数、密度分布
缓存层用 Redis——位置数据每秒多次更新,不直接写 MySQL,API 读 Redis 返回,响应时间压进毫秒级。
关于前端
师弟做的,用的Vue,等我待会儿找他搞张截图。
技术栈
| 层 | 技术 |
|---|---|
| 语言 | Go · Python |
| 消息队列 | Kafka · ZeroMQ |
| 推理 | PyTorch · Ultralytics YOLO · OpenCV |
| 后端框架 | Gin |
| 缓存 & 持久化 | Redis · MySQL |
| 部署 | Docker · Docker Compose · GitHub Actions CI/CD |
一点体会
这个项目的难点不在某个单一算法,而是真实场景下的工程整合——多路视频的帧同步、不同模块间的通信选型(Kafka vs ZeroMQ 各管各的)、Go 和 Python 跨语言协作。前期也没少踩坑,比如前期用的激光雷达方案因为港区粉尘和震动根本稳不住。好在后来系统切到纯视觉路线,算是从头折腾到尾把链路跑通了。回头看,这些实践经验比算法本身更有价值。